高性能计算赛道的深脑链,是 Web3.0 时代的刚需吗?
高性能计算赛道的深脑链,是 Web3.0 时代的刚需吗?
区块律动:https://www.theblockbeats.info/news/24626?search=1 2021 年 06 月 01 日 17:30
市场需要一个低成本、高性能的统一的去中心化计算网络方案。
近年来,随着互联网基建的日益成熟,大数据分析、万物互联、人工智能等领域呈几何增长趋势迅猛发展。据统计,2020 年中国人工智能市场规模已超 4000 亿人民币,平均复合增长率达 40%。
国外机构的发展速率更是不容小视,顶级 AI 机构 Tractica 预测,人工智能驱动的硬件和软件基础设施全球市场总量在 2025 年增长至 1154 亿美元。其中 AI 云计算基础设施占比将达到 70%。
是的,支撑着这一切的,是海量的算力。传统的超大型数据中心已经无法满足市场需求,需要调度管理不同级别的数据中心(云计算节点、城域节点、边缘节点),市场需要一个低成本、高性能的统一的去中心化计算网络方案。
去中心化高性能算力网络 DBC
传统云计算由三部分组成:计算、存储,以及 CDN(内容传输网络)。储存赛道中的龙头当属 Filecoin,老牌的 Arweave 和 Storj 也表现不俗。再看 CDN 领域,Theta 一枝独秀。在计算方面,近期刚刚上线主网的 DFINITY 霸占了 CPU 计算的领地,而在 GPU 计算领域也有很多代表项目,深脑链就是其中之一。
相比于 DFINITY 的 CPU 计算,GPU 更注重于高性能计算,尤其是对于人工智能领域,其背后的深度学习算法与 GPU 计算十分吻合。无论是与人类顶级象棋高手博弈的 AlphaGo,还是日常陪伴在我们身边的智能机器人「小度」,似乎充满人工智能、万物皆可互联的场景近在眼前。除此之外,自动驾驶、生物制药、人工智能、云游戏、区块链等众多场景都需要高性能算力的支持。去年英伟达市值超越英特尔,这也标志着传统云计算从 CPU 向 GPU 转移的主流趋势。尤其是视觉渲染赛道,目前全球每年的市场量级在 20 万 GPU 以上。
深脑链技术上实现了基于区块链技术的全球去中心化 GPU 高性能算力调度网络。DBChain 为开源的 GPU 算力池和 GPU 云平台,全球范围内的闲置 GPU 算力资源都可以自由地加入深脑链算力网络,通过网络协调调配,域内算力将最高效化利用,并形成一个完整的生态闭环。深脑链的核心是破解人工智能算力昂贵这一难题,并实现海量算力的无限扩容,从而推动人工智能算力的普及和平民化,加速人类社会向智能化迈进。
DBC 网络中目前已经有超过 6000 张 GPU,并且随着算力生态建设的开始,网络中节点数量将会越来越多。每年有 4 亿 DBC 的算力生态建设奖励以激励高性能算力提供者,并吸引更多 GPU 资源进入到生态中。
在未来 ETH2.0 上线之时,网络共识协议将从 PoW 转变为 PoS 机制,原以太坊网络中的显卡大概率将成为闲置资源。其中高端显卡或也将参与到深脑链中进行算力生态建设。
从 NEO 到 Substrate 应用链
此前,深脑网络建立在 NEO 生态中,以智能合约进行实现。然而,智能合约的限制使得很多复杂的功能难以实现。现在,深脑转入了波卡生态。
从安全角度来看,Polkadot 网络实行共享安全模式,Substrate 链在拍得平行链插槽的情况下即可加入到 Polkadot 的系统中共享中继链的安全。
Substrate 应用链作为深脑链的底层开发框架能够实现深脑协议的完全定制化,将深脑网络的业务逻辑深度贯彻执行。同时,Substrate 应用链赋予了深脑网络与其他应用链通过 IBC 及 XCMP 进行互操作的能力,同时波卡生态的转接桥设施也已就绪,这使得深脑链能够与其他现存公链进行交互。另外,波卡的的治理机制比较完善,且生态庞大,与深脑的业务有融合点,协议间的组合将产生无法预估的协同效应。
底层的稳定带来的是生态的发展,在区块链、人工智能、云游戏、视觉渲染、生物制药、半导体仿真模拟等各个场景都得到广泛的应用,为众多企业提供了高性价比 GPU 算力,累计全球近 50 家厂商(开发者)基于深脑链网络部署高性能 GPU 云平台,服务数百家企业以及数万 AI 开发者群体。
去中心化算力网络的治理
深脑链在主网上线后将会走向去中心化治理,社区内成员的意见将对深脑协议产生更重要的作用,未来无论是技术开发、市场宣传、发展策略等等都将通过深脑链去中心化治理平台进行治理。任何人持有 DBC 代币的用户,都有权进行提案,提案可以是任何内容,最后提案是否执行,将通过社区投票的方式自动化完成。
例如 DBC 持币者 A 为技术开发人员,并认为功能 X 对于深脑链非常重要,且自己有开发能力去完成该功能的开发。此时,技术人员将发起提案,提案中将详细描述功能需求对深脑链的重要性,然后在社区发起投票,从而获取开发资金。最终所有持有 DBC 代币的社区成员都可以参与投票,并决定是否对此议案进行拨款。
再比如,任何关于 DBC 网络发展的机制改进或者重大产品功能的部署,也都会由社区投票决定。所有关于 DBC 协议的修改,都将以去中心化的形式完成。
深脑链基金会最终的目标是,争取在主网上线一周年后完成 DBC 治理的完全去中心化。未来通过参与 DBC 链上治理将会是一种个人创业非常好的途径,DBC 社区为所有 Web3.0 时代创业者创造了一个公平自由的平台。
DBC 代币经济模型
DBC 代币的价值与 DBC 网络中 GPU 被租用数量相关,被租用的 GPU 数量越多,DBC 价值越大。
用户每笔 GPU 服务器租用交易金额销毁比例是 100%。对于高性能算力提供者来说,每张显卡需要质押定量的 DBC 并进行锁仓。以即将开启的算力银河竞赛为例,银河竞赛中每张显卡质押 10 万个 DBC,需要质押至少 365 天;当机器在线超过 365 天后,且没有用户使用超过 10 天,可以退出质押停止算力生态建设,3 天内释放质押 DBC,且之前获得的奖励继续线性释放。
当全网显卡质押 GPU 数量超过 10000 卡,新增显卡的 DBC 质押数量将自动调整,根据流动 DBC 数量以及 DBC 价格调整。从 10001 卡开始,每卡质押总数公式为: 10 万 ×10000/n;如果按照上述公式核算,单卡质押超过 5 万元人民币,那么质押按照最多 5 万元人民币计算。
若全网 5000 卡,将会有 5 亿个 DBC 被锁仓,同时每个月将有 500 万人民币的租金用来销毁 DBC,按照 DBC 价格 0.1 元计算,每月将会有 5,000 万个 DBC 被销毁,每年超过 6 亿个 DBC 被销毁;在实际完成质押和销毁的过程中,DBC 价格是浮动的,DBC 价格越高,单卡单月销毁 DBC 数量会越来越少。
此代币经济模型不光确保了 DBC 总量的通缩趋势作为价值支撑,也保证了流通盘的稳定,以此确保 DBC 网络的可持续发展。
为了回馈深脑链的早期 GPU 算力贡献者,深脑链预计将在北京时间 2021 年 6 月 23 号之后开启银河算力竞赛。该竞赛没有任何限制条件,只要显卡达到要求,任何高性能算力提供者都可以参加。在 6 月 23 日 10:00 后,任何时刻只要主网参与质押的算力生态建设机器显卡数量大于等于 5,000 张,竞赛就立刻开始。本次银河算力竞赛将持续 1 个月。排名前 5 的算力池,DBC 团队将额外拿出 3000 万枚 DBC 作为奖励,按照算力占比进行分配。
参赛的 GPU 也有要求,以下为参赛 GPU 服务器最低要求:
1)GPU:2 卡或者 4 卡;英伟达 Nvida 系列显卡,最低要求 8G 显存;考虑到出租率,显卡类型推荐 2080ti、3060ti、3070、3070ti、3080、3080ti、3090 等;
2)内存:448 G (4 卡) 或者 224 G (2 卡),(计算公式:GPU 数量*112);
3)CPU: 2 卡-1 颗 CPU,4 卡-2 颗 CPU,Intel,V3 以上,主频 2.5Ghz、睿频 3.0Ghz 及其以上,单颗 CPU 10 核及其以上;
4)硬盘:系统盘 512g(SSD),数据盘 2T(机械硬盘);
5)网络带宽:2 卡-10M//台 以上;4 卡-20M/台 以上;
6)有独立固定 IP ;
7)机器放在标准数据中心 T3 级别以上,保持网络和电的稳定性。
只有 GPU 服务器满足最低要求,才可以获得奖励。单个 GPU 算力点数有两个影响指标:GPU CUDA Core 数量 和显存大小,GPU CUDA Core 数量影响占比 70%,显存影响占比 30%。
需要注意的是,DBC 在线奖励数量根据算力供给者在 DBC 全网算力值中的占比进行等比例分配,影响 DBC 在线奖励的 4 要素:GPU 算力值、GPU 在线数量、单个 DBC 钱包下的 GPU 在线数量、GPU 租用状态;
a. GPU 算力值计算公式:
算力值=13+0.7×√(cuda 数量)+0.3× 显存/24×√(cuda 数量)
上述公式中,√ 表示平方根,部分显卡参考值如下:
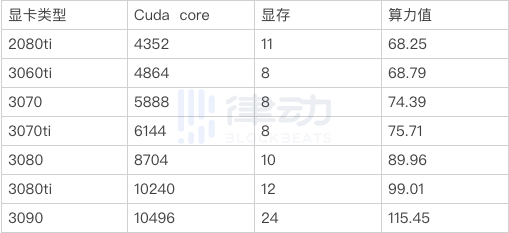
b. 单个 DBC 钱包下的 GPU 在线数量,每多一个 GPU,所有机器算力值增加 0.01%,一直到增加 10% 为止;
c. 在线租用状态:GPU 被租用的情况下,算力值增加 30%;
就像 DeFi 生态中的黑客松一样,银河竞赛一方面不仅可以让玩家了解深脑链,也可以为项目筛选出忠实用户。
作为去中心化计算赛道穿越牛熊的项目,深脑链正在实现着大规模落地。而随着主网的启动,深脑链在 Web3.0 世界的表现,让我们也拭目以待。